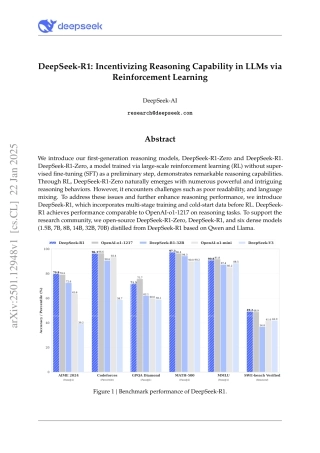
DeepSeek-R1:IncentivizingReasoningCapabilityinLLMsviaReinforcementLearningDeepSeek-AIresearch@deepseek.comAbstractWeintroduceourfirst-generationreasoningmodels,DeepSeek-R1-ZeroandDeepSeek-R1.DeepSeek-R1-Zero,amodeltrainedvialarge-scalereinforcementlearning(RL)withoutsuper-visedfine-tuning(SFT)asapreliminarystep,demonstratesremarkablereasoningcapabilities.ThroughRL,DeepSeek-R1-Zeronaturallyemerg...
 GB-55008-2021-混凝土结构通用规范(正式版)2777页
GB-55008-2021-混凝土结构通用规范(正式版)2777页 国金证券:海水无淡化原位制氢技术海试成功,打开氢能业务成长空间5068页
国金证券:海水无淡化原位制氢技术海试成功,打开氢能业务成长空间5068页 企业绿色电力采购与应用:中国市场进展与展望2024年度报告4039页
企业绿色电力采购与应用:中国市场进展与展望2024年度报告4039页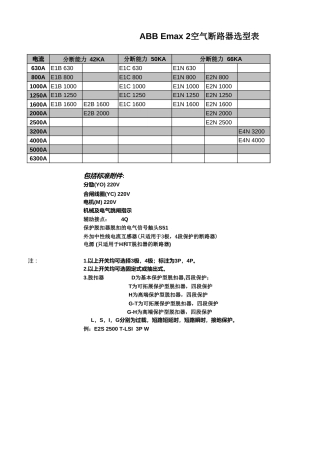 ABB电气设备简明选型工具2950页
ABB电气设备简明选型工具2950页 综合视角下的气候适应:对粮食供应、城市生活、河流运输和生态系统的长期影响2923页
综合视角下的气候适应:对粮食供应、城市生活、河流运输和生态系统的长期影响2923页 现浇空心板专项施工方案2020年(已通过专家论证)word125页14133页
现浇空心板专项施工方案2020年(已通过专家论证)word125页14133页 中邮证券:当前时点_储能行业需求如何92621页
中邮证券:当前时点_储能行业需求如何92621页 国信证券:AI文字识别龙头,扫描全能王和商业大数据齐头并进11338页
国信证券:AI文字识别龙头,扫描全能王和商业大数据齐头并进11338页 砂轮打磨机切割机手磨机安全操作培训1549页
砂轮打磨机切割机手磨机安全操作培训1549页 DL 5190.2-2019 电力建设施工技术规范 第2部分:锅炉机组10191页
DL 5190.2-2019 电力建设施工技术规范 第2部分:锅炉机组10191页 生态环境部:2025、2026年度全国碳排放权交易市场发电、钢铁、水泥、铝冶炼行业配额总量和分配方案(征求意见稿)2283页国信证券:AI文字识别龙头,扫描全能王和商业大数据齐头并进11338页GB-55008-2021-混凝土结构通用规范(正式版)2777页
生态环境部:2025、2026年度全国碳排放权交易市场发电、钢铁、水泥、铝冶炼行业配额总量和分配方案(征求意见稿)2283页国信证券:AI文字识别龙头,扫描全能王和商业大数据齐头并进11338页GB-55008-2021-混凝土结构通用规范(正式版)2777页 国家电网设备〔2022〕89号 国家电网有限公司关于进一步加强生产现场作业风险管控工作的通知102668页
国家电网设备〔2022〕89号 国家电网有限公司关于进一步加强生产现场作业风险管控工作的通知102668页 图集 17J008 挡土墙(重力式、衡重式、悬臂式)(2017年版)73282页
图集 17J008 挡土墙(重力式、衡重式、悬臂式)(2017年版)73282页 单、双地线保护范围、单避雷针保护范围计算工具269页
单、双地线保护范围、单避雷针保护范围计算工具269页 天风证券:电力行业并购重组系列二:电网资产梳理529页国金证券:海水无淡化原位制氢技术海试成功,打开氢能业务成长空间5068页
天风证券:电力行业并购重组系列二:电网资产梳理529页国金证券:海水无淡化原位制氢技术海试成功,打开氢能业务成长空间5068页 广东电力市场现货电能量交易实施细则(2026年修订)303422页
广东电力市场现货电能量交易实施细则(2026年修订)303422页 中泰证券:配储经济性提升,工商储需求亟待爆发52930页
中泰证券:配储经济性提升,工商储需求亟待爆发52930页


